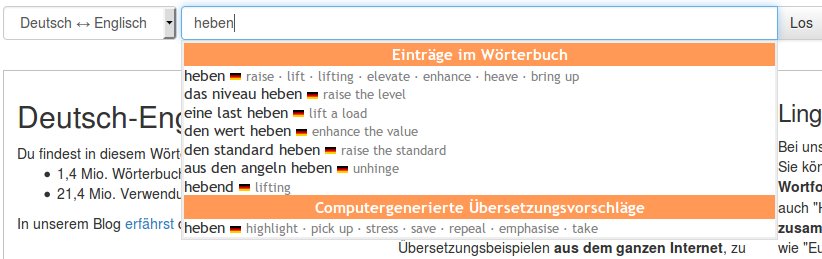
Um im Kontextwörterbuch die Treffer (also die Beispielsätze) nach bestimmten Kriterien einzuschränken, müssen Sie zuerst die Filter einblenden:
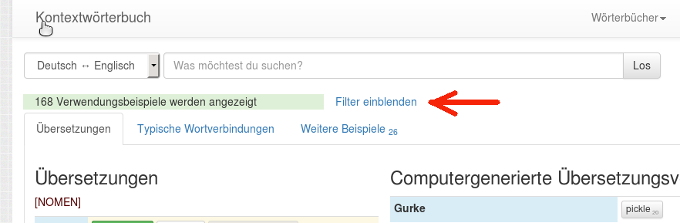
Die aufgeklappte Filter-Box sieht dann so aus:
 Es gibt fünf Filter-Kriterien:
Es gibt fünf Filter-Kriterien:
- TLD Deutsch: Top level domain für die deutsche Seite
- TLD Englisch: Top level domain für die englische Seite
- Korpustyp
- Host
- Sachgebiete
Die Kriterien und ihre Verwendung werden im folgenden genauer erklärt.
TLD Deutsch
Hier können die Treffer auf eine sogenannte top level domain (TLD) eingeschränkt werden. Als top level domain wird der letzte Teil einer Web-Adresse (Domain) hinter dem letzten Punkt bezeichnet, z.B. de oder com. Wenn Sie eine der blau dargestellten TLDs auswählen, werden nur noch Sätze angezeigt, deren deutsche Seite von einer Webseite mit der entsprechenden TLD stammt. Es wird also nur noch eine Teilmenge der vorhandenen Treffer angezeigt. Wenn Sie z.B. nur Sätze sehen wollen, deren deutsche Seite von einer Webseite aus der Schweiz stammt, dann wählen Sie unter TLD Deutsch ch aus.
Die tiefergestellten Zahlen neben jeder TLD geben die Anzahl der jeweils vorhandenen Beispielsätze an.
Da nicht alle Beispielsätze aus dem Web stammen, sondern auch aus parallelen Korpora wie DGT-TM, gibt es auch eine TLD namens ohne. Wenn Sie diese auswählen, werden nur noch Sätze angezeigt, die nicht aus dem Web, sondern aus einem Parallelkorpus stammen.
TLD Englisch
Hier können Sie die gewünschte Top level domain für die englische Seite einschränken. Wenn Sie z.B. nur Sätze sehen wollen, deren englische Seite von einer Webseite aus Großbritannien stammt, wählen Sie uk als TLD Englisch.
Mehrere Filterkriterien können miteinander kombiniert werden. Wenn Sie beispielsweise nur Sätze sehen wollen, deren deutsche Seite von einer Webseite aus Österreich stammt und deren englische Seite von einer Webseite aus Großbritannien, dann wählen Sie at als TLD Deutsch und anschließend noch uk als TLD Englisch.
Korpustyp
Jeder Beispielsatz gehört zu genau einem Korpustypen. Es gibt die folgenden Korpustypen:
| Korpustyp |
Beschreibung |
| Webseite |
gecrawlte Sätze aus dem WWW |
| EU Webseite |
gecrawlte Sätze aus dem WWW von der Domain europa.eu |
| EU DCEP |
Digital Corpus of the European Parliament |
| EU DGT-TM |
DGT Translation Memory |
| EU IATE |
The EU’s multilingual term base |
| EU |
ECDC-TM, EAC-TM |
| Parlamentsdebatte |
Das europarl-Korpus |
| ECB |
European Central Bank |
| EMEA |
European Medicines Agency |
| commoncrawl |
Korpus aus gecrawlten Sätzen |
| Fachtext |
Wissenschaftliche Abstracts aus Abschlussarbeiten, Dissertationen und Fachzeitschriften |
| Gesetz |
Die UN-Menschenrechtserklärung und die EU-Verfassung |
| Literatur |
Literaturübersetzungen ( H.C. Andersen, H. de Balzac, F.M. Dostojewski, A.C. Doyle, G.E. Lessing, G. Orwell, L. Carroll, C. Dickens, G. Flaubert, J.W. Goethe, L. von Sacher, J. Spyri, T. Storm und O. Wilde) |
| OpenOffice3 |
OpenOffice-Dokumentation |
| Politische_Rede |
Reden deutscher Politiker 2004-2007 sowie J.F. Kennedys Berliner Rede 1963 |
| Pressemeldung |
Pressemeldungen der Bundesregierung bzw. einzelner Ministerien |
| UN |
Das MultiUN-Korpus |
| Untertitel |
Untertitel von Filmen und Serien |
| Wikipedia |
Übersetzungen von Wikipedia-Artikelnamen und unser Wikipedia Parallel Quotations-Korpus |
| Zeitungskommentar |
Das news-commentary-Korpus |
Host
Wenn Sie einen Host auswählen, werden nur noch Beispielsätze angezeigt, die von diesem Host stammen. Als Beispiel die Filter-Box und die Übersetzungen für das Suchwort „Läufer“:
Unter den Übersetzungen von „Läufer“ sind diejenigen hervorgehoben (anklickbare Buttons), für die Beispielsätze gefunden wurden. Man erkennt Sie auch an den tiefergestellten Zahlen: sie haben eine Zahl größer Null (die Zahl steht für die jeweils gefundenen Sätze). Alle Lesarten von Läufer sind vertreten: Sport (runner, halfback), Schach (bishop), Technik (rotor, stretcher) und der Teppich. Wenn Sie nun chessbase als Host auswählen, werden nur noch Sätze zur Schach-Lesart gefunden:
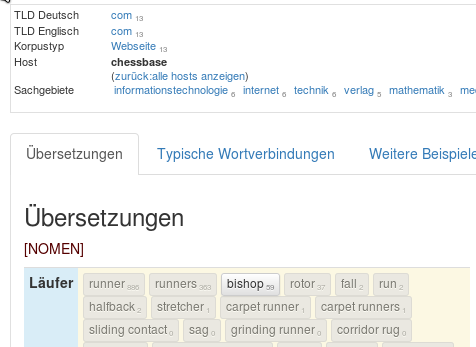 Wenn Sie dagegen die Beispielsätze auf den Host berlin-laeuft einschränken, erhalten Sie nur noch Sätze zur Lesart runner:
Wenn Sie dagegen die Beispielsätze auf den Host berlin-laeuft einschränken, erhalten Sie nur noch Sätze zur Lesart runner:
 Sachgebiete
Sachgebiete
Hier kann die Menge der angezeigten Beispielsätze auf ein Sachgebiet eingeschränkt werden. Sachgebiete gibt es allerdings nur bei den Korpustypen „Webseite“ und „EU Webseite“. Jede gecrawlte Webseite wurde mit einem automatischen Verfahren ein bis drei Sachgebieten zugeordnet. Nachfolgend die vollständige Liste aller Sachgebiete (das Sachgebiet unbekannt gilt für alle Sätze ohne Sachgebietsklassifizierung):
unbekannt, technik, informationstechnologie, internet, tourismus, e-commerce, verlag, theater, mode-lifestyle, schule, universitaet, verwaltung, transport-verkehr, informatik, kunst, musik, film, infrastruktur, staatliche-entscheidungsorgane-und-oeffentliches-finanzwesen, oekonomie, media, finanzmarkt, wirtschaftsrecht, auto, politik, sport, steuerterminologie, jagd, verkehr-kommunikation, marketing, boerse, radio, medizin, personalwesen, rechnungswesen, ressorts, immobilien, markt-wettbewerb, religion, astrologie, flaechennutzung, mythologie, militaer, psychologie, transaktionsprozesse, soziologie, bahn, unternehmensstrukturen, gastronomie, physik, literatur, verkehrssicherheit, weltinstitutionen, oekologie, pharmazie, jura, astronomie, bau, gartenbau, verkehr-gueterverkehr, handel, versicherung, raumfahrt, luftfahrt, foto, archäologie, meteo, zoologie, forstwirtschaft, geografie, geologie, nautik, philosophie, botanik, architektur, biologie, vogelkunde, mathematik, landwirtschaft, historie, chemie, verkehrsfluss, linguistik, bergbau, finanzen, typografie, controlling, mobilfunk-telekommunikation