
Ontology building
Semantic similarity
Visualisation of lexical fields
DISCO
compute semantic similarity between words
What is DISCO?
DISCO (extracting DIstributionally related words using CO-occurrences) is a Java application
that allows to retrieve the semantic similarity between arbitrary words and phrases. The similarities
are based on the statistical analysis of very large text collections. The tool runs on all popular
operating systems, including Windows, Linux, Solaris, and MacOS.
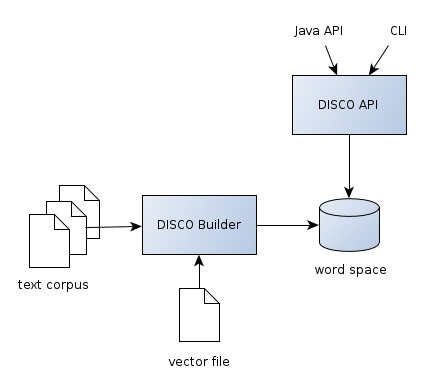
DISCO consists of
- the DISCO API to query an existing database of similar words and
- DISCO Builder which allows to create a database of similar words from a text corpus.
The DISCO Java API supplies methods like the following:
- retrieve the semantically most similar words for an input word, e.g. shy → timid quiet introverted lonely cautious awkward clumsy soft-spoken gentle
- retrieve the value of the semantic similarity between two input words: sim(gasoline, oil) = 0,522; sim(gasoline, lemonade) = 0,159
- retrieve collocations for an input word: beer → keg brewed brewing lager Pilsener brewers brewery Budweiser mug ale
- compute the semantic similarity between short texts (e.g. phrases, sentences, or paragraphs)
- cluster similar words, including output to CLUTO
- "grow set": find more words that are similar to all words in a set
DISCO can also be queried from the command line. Furthermore, a DISCO plugin is available for the ontology editor Protégé.
DISCO is described in the following conference papers:
Peter Kolb. Experiments on the difference between semantic similarity and relatedness. In Proceedings of the 17th Nordic Conference on Computational Linguistics - NODALIDA '09, Odense, Denmark, May 2009.
Peter Kolb. DISCO: A Multilingual Database of Distributionally Similar Words. In Proceedings of KONVENS-2008, Berlin, 2008.
Overview
The DISCO API needs a pre-computed database of word similarities. This database is also called a
word space (a.k.a. "language data packet"). A word space contains for each word a
word vector (a.k.a "word embedding") and (depending on the type of the word space) the most
similar words (i.e. those words whose word vector is highly similar to the word vector of the target
word).
In DISCO, there are two types of word spaces:
- COL: word spaces of type COL only contain the word vector but not the most similar words for each word. Therefore, some of the API methods can not be used with wordspaces of type COL. The advantage of COL word spaces is that they are faster to build and have smaller size.
- SIM: word spaces of type SIM contain both the word vector and the most similar words for each word.
You can use DISCO Builder to generate a word space from a text corpus yourself. DISCO Builder also allows to convert vector files that were produced with fastText, word2vec or GloVe to a DISCO word space. Additionally, there are ready-to-use word spaces for many languages available on the download page.
Applications and online demo
There is a wide range of possible applications for DISCO's semantic similarities, reaching over all areas of natural language processing. The following list is not exhaustive:
- Translation: context-sensitive translation. Example: The bank closes the account. A dictionary lists two possible translations for bank into German: bank → Bank (financial institution) and Ufer (river bank). The dictionary also gives Konto as German translation of account. Now DISCO delivers the similarity values: sim(Bank, Konto) = 0,181 and sim(Ufer, Konto) = 0,022, so that Bank can be chosen as correct translation in the context of the sentence.
- Search engines: associative search using semantically similar words; automatic search term expansion.
- E-Learning: generation of (bilingual) word fields for a domain.
- context-sensitive spelling correction: ranking of proposed corrections not only according to string similarity, but also semantic similarity with the context.
- context-sensitive Thesaurus: propose synonyms that fit into the context.
- Ontology learning: DISCO supplies semantically similar words for an input word, that can be further classified into the type of the similarity relation (synonym, hyponym, antonym etc.). There is a DISCO plug-in available for the well known ontology editor Protégé.
- Text Tiling: automatically divide texts into coherent units.
- Speech recognition and OCR: construction of class-based language models.
Our online demo Wortsurfer shows that DISCO can also be used as a Thesaurus.
References
The references page lists scientific publications by DISCO users.
Available languages
You can find ready-to-use word spaces on the download page.
Download and installation
- Step 1: download the DISCO API disco-3.0.0-all.jar.
- Step 2: download one of the word spaces.
- Step 3: now you can query DISCO from the command line:
java -jar disco-3.0.0-all.jar WORD-SPACE-DIRECTORY -bn house 12
outputs the twelve semantically most similar words for house.
You need a Java 8 Runtime Environment. If Java isn't installed on your system, you can download it from www.java.com.
Command line usage
DISCO can be queried from the command line. Just type:
java -jar disco-3.0.0-all.jar WORD-SPACE-DIRECTORY OPTIONS
The possible options include:
-bn WORD N: outputs the N semantically most similar words for WORD. Example:
-bn mouse 10 → mice joystick rat Mouse keyboard rats button USB cursor printer rabbit.
-bc WORD N: outputs the N most significant collocations for WORD. Example:
-bc decision 7 → unanimous overturned reversed upheld rescinded controversial appealed.
-s WORD1 WORD2 SIM-MEASURE: outputs the value of the first-order semantic similarity between the two input
words (the value is between 0 and 1).
-s2 WORD1 WORD2: outputs the value of the second-order semantic similarity between the two input
words (the value is between 0 and 1).
-cc WORD1 WORD2: outputs the common context of the two input words.
-f WORD: outputs the corpus frequency for WORD.
-n: ouputs the number of words that can be queried.
-wl FILE: prints the complete word frequency list to the file.
Call disco-3.0.0-all.jar without parameters to get the full list of options.
Java API
DISCO can be integrated into your own applications using the Java API. The Java API supplies several methods to retrieve semantically similar words, the semantic similarity between words and phrases, collocations, corpus frequencies etc. You can find more information in the API documentation (javadoc) and on GitHub.
License conditions
The DISCO API is open source and licensed under Apache License, version 2.0.
DISCO Builder is licensed under Creative Commons Attribution-NonCommercial license.
Most word spaces are available under Creative Commons Attribution license. A few are licensed Creative Commons Attribution-NonCommercial.
If you are interested in the commercial use of DISCO Builder or a word space that is licensed Creative Commons Attribution-NonCommercial contact Peter Kolb (peter.kolb@linguatools.org). We can also create customized word spaces for your desired domains or languages on request.
Acknowledgements
DISCO uses the Lucene index and Sux4J.
The DISCO language data were partly compiled on the basis of the following freely available electronic
text collections:
- the international versions of the Wikipedia. Text corpora extracted from the Wikipedia are available here.
- the Europarl corpus
- the JRC-ACQUIS corpus
- the German and English Project Gutenberg.